How a mom-and-pop grocery store owner built an enterprise-grade analytics stack in a weekend
Things are about to get really weird
So… You may recall my post from last October where I waxed poetic about why I was leaving Alteryx behind for Databricks, and my post from November where I used ice cream sandwich sales data to catch a bug in our POS system. If you read those, you know I've been on a bit of a journey building out a real analytics stack for Three Sisters Provisions, our little grocery and café in Cohasset, MA.
What I haven't told you yet is what happened when I decided to stop dabbling and go all-in with my new bestie, Claude.
Over the past few days, I sat down with Claude — Anthropic's AI, which I've been using in a Claude Project specifically dedicated to this work — and we built something I genuinely didn't think was possible without a team of data engineers and several weeks of billable hours.
Let me tell you what we built. And then let me tell you why it matters way beyond my wife’s adorable little store.
The Stack
Here's what's running nightly at Three Sisters Provisions:
A Bronze layer pulls raw orders data from the Toast POS API and weather data from Open-Meteo's historical archive and forecast APIs.
Silver transforms and cleans that raw data — exploding order line items, fixing time zone issues (Toast stores timestamps in UTC, which caused some fun debugging), and building out a clean order and items table.
Gold aggregates everything into three production tables: a daily sales summary with weather, an hourly sales summary for the "how are we doing today" view, and a daily category breakdown showing revenue by product category.’
On top of that, we built a few Prophet-based machine learning forecast models — one for revenue, one for order count — both logged and versioned in MLflow, registered in the Databricks Model Registry with a @production alias, and running nightly to write 30 days of forward predictions into the same Gold table alongside the actuals.
The whole thing runs as scheduled Databricks jobs.
Weather ingests at 2:14 AM. Sales ingests and transforms and rolls up to Gold starting at 2:59 AM. Forecast generation runs after that. Every morning when I wake up, the data is current and the next 30 days of predictions are fresh.
I also built a reference table for special events — town strolls, catering days, future closures — with a little management notebook so my wife or or nephew can log a new event without touching a line of model code.
Oh, and there's a validation cell in the Gold notebook that actually asserts revenue matches Silver within 1% tolerance and will fail the job loudly if something's wrong. Because silent bad data is worse than no data.
The Mistakes Were Educational
I would be doing you, dear reader, a disservice if I made this sound entirely smooth. It was not entirely smooth.
We discovered about halfway through that a join between the orders table and the items table was multiplying revenue by the average number of items per order — roughly 4.3x inflation on every single number. The forecast model trained on those numbers for a while before we caught it. The result was a Friday revenue prediction of $7,646 when actual Friday revenue tends to be closer to $2,500-$3,000. Once we caught the root cause, fixed the join, rebuilt the Gold table, and retrained the model, the predictions came back down to earth and the implied average ticket size — revenue divided by order count — started making sense in the $20-$29 range. This sort of catch is still a human-driven value add. I also noticed Tips, which are only enabled on Online Orders, for reasons I don’t entirely understand, were flowing into Net Revenue. Big no-no.
We also discovered that Spark SQL doesn't support FIRST(col ORDER BY other_col) syntax like PostgreSQL does. And that sample_weight in Prophet's model.fit() isn't supported in the serverless-installed version. And that moving a notebook from Drafts to a shared workspace folder breaks the job task path references. Each of these is the kind of thing that costs a consulting engagement a day or two of billable debugging. With Claude, we caught and fixed them in seconds. These are examples of things that Claude figured out for me. And more often than not, solved for before I knew it was a problem. Candidly, I don’t think I knew this until the time of writing this blog together.
What This Means for Data Engineering Consulting
I say this with genuine affection for my colleagues in the data engineering world, because I have spent years selling their services: the ground is shifting under this business model.
The traditional engagement goes something like this: a client needs a data pipeline. They hire a firm. The firm scopes the work, assembles a team, runs a discovery phase, builds out the architecture, writes the code, documents it, hands it over, and charges somewhere between $150 and $400 an hour for all of the above. Two yeas ago, for a project like what I just described — Bronze/Silver/Gold medallion architecture, API ingestion, weather integration, ML forecasting with MLflow, nightly scheduling — you're probably looking at an 8-16 week engagement at a meaningful blended rate.
Folks: I built it in a weekend, often while playing games on my other monitor. With an AI. For the cost of a Claude Max subscription and some Databricks compute that I think is going to total around $50, give or take.
Now — and this is important — I want to be clear about what I had going for me. I have spent years at Databricks selling professional services. I understand the concepts, the lingo, even if I hadn't implemented them myself. I’ve done much the same work in other platforms, like Alteryx, that I was doing today. I knew enough to ask the right questions, push back when something felt architecturally wrong, and insist on doing things properly rather than patching symptoms. When Claude tried to fix a broken forecast by throwing code into a notebook rather than fixing the underlying join bug, I was the one who said "wait, let's step back and think about the root cause." That instinct matters enormously.
I'm not saying data engineering expertise is obsolete…
I'm saying the delivery model for this sort of expertise is changing in ways that should make everyone in this space think carefully.
What's changing rapidly is the ratio: The ratio of experienced human judgment to commodity implementation work is shifting dramatically in favor of judgment. The judgment — knowing what to build, why this architecture and not that one, when to be suspicious of a number, what the business actually needs from its data — that's worth as much as it ever was. Maybe more, because now the implementation can move so fast that bad architectural decisions compound just as quickly as good ones.
What's diminishing in value is the pure hours of writing boilerplate pipeline code, setting up MERGE statements, fixing timezone issues, debugging Spark SQL syntax errors. An AI assistant can do a lot of that work. Not all of it, not without supervision, and not without someone who knows enough to catch it when it's wrong. But enough of it that a 12-week engagement for a reasonably straightforward data pipeline feels increasingly hard to justify.
The Good News: What This Means for Small Businesses
Here's the thing that actually keeps me up at night, in a good way.
For the past decade or so, sophisticated data infrastructure has been the exclusive province of companies with budgets large enough to hire data teams or engage consulting firms. A retailer with three locations and $5M in revenue doesn't get a medallion lakehouse architecture with ML forecasting. They get a spreadsheet and maybe a Shopify analytics dashboard.
What I built at Three Sisters Provisions is — objectively — more sophisticated than what most mid-market retailers have. A nightly-retraining Prophet model with cross-validation, hyperparameter tuning, seasonal priors from comparable historical data, confidence intervals, and forecast accuracy tracking by horizon day. A validation layer that reconciles Gold against Silver on every run and fails loudly on data quality issues. Full Unity Catalog metadata with column-level comments. A reference table architecture so special events are maintained in one place and all downstream models pick them up automatically.
I'm a mom-and-pop grocery store. We sell sandwiches and wine and the best sourdough on the South Shore: Kneady Mama bread. And I have a more rigorous analytics stack than most companies ten times our size.
That gap — between what sophisticated businesses have and what small businesses have — is compressing fast. The question for small business owners isn't really "can I afford enterprise-grade analytics?" anymore. The question is "do I understand my own business well enough to direct an AI to build it for me?"
That second question is harder than it sounds. You need to know what questions you want to answer. You need to understand enough about your data to catch it when something looks wrong. You need to be willing to go slowly on architecture decisions even when the temptation is to just get something running. And you need the patience to iterate — because the first version of anything will have bugs, and finding them is part of the process.
But if you have those things? The tools are there.
What This Means for Businesses That Aren't Plugged In
This is the part I find most interesting from a macro perspective.
There's a class of business — probably the majority of businesses — that is going to wake up in three to five years and find that their competitors who embraced this shift have a genuinely unfair informational advantage. Not because they bought expensive software. Not because they hired an army of data scientists. But because they spent some time learning to work with AI tools rather than waiting for someone to hand them a finished product.
The gap between plugged-in and not-plugged-in isn't a technology gap. Databricks has a free tier. Claude has plans that cost less than a dinner out. The gap is a curiosity and willingness gap. The businesses that win in this new world are going to be the ones where the owner, or someone close to the owner, got curious about what was possible and started experimenting.
I'm not a data engineer. I'm a reformed Sales Ops Analyst and a sales guy with a blog called questionable decision-making. And I built a production ML forecasting pipeline. In a weekend.
The tools are genuinely accessible now. The question is whether you're willing to pick them up.

Over the past few days, I sat down with Claude — Anthropic's AI, which I've been using in a Claude Project specifically dedicated to this work — and we built something I genuinely didn't think was possible without a team of data engineers and several weeks of billable hours.
Let me tell you what we built. And then let me tell you why it matters way beyond my wife’s adorable little store.
The Stack
Here's what's running nightly at Three Sisters Provisions:
A Bronze layer pulls raw orders data from the Toast POS API and weather data from Open-Meteo's historical archive and forecast APIs.
Silver transforms and cleans that raw data — exploding order line items, fixing time zone issues (Toast stores timestamps in UTC, which caused some fun debugging), and building out a clean order and items table.
Gold aggregates everything into three production tables: a daily sales summary with weather, an hourly sales summary for the "how are we doing today" view, and a daily category breakdown showing revenue by product category.’
On top of that, we built a few Prophet-based machine learning forecast models — one for revenue, one for order count — both logged and versioned in MLflow, registered in the Databricks Model Registry with a @production alias, and running nightly to write 30 days of forward predictions into the same Gold table alongside the actuals.
The whole thing runs as scheduled Databricks jobs.
Weather ingests at 2:14 AM. Sales ingests and transforms and rolls up to Gold starting at 2:59 AM. Forecast generation runs after that. Every morning when I wake up, the data is current and the next 30 days of predictions are fresh.
I also built a reference table for special events — town strolls, catering days, future closures — with a little management notebook so my wife or or nephew can log a new event without touching a line of model code.
Oh, and there's a validation cell in the Gold notebook that actually asserts revenue matches Silver within 1% tolerance and will fail the job loudly if something's wrong. Because silent bad data is worse than no data.
The Mistakes Were Educational
I would be doing you, dear reader, a disservice if I made this sound entirely smooth. It was not entirely smooth.
We discovered about halfway through that a join between the orders table and the items table was multiplying revenue by the average number of items per order — roughly 4.3x inflation on every single number. The forecast model trained on those numbers for a while before we caught it. The result was a Friday revenue prediction of $7,646 when actual Friday revenue tends to be closer to $2,500-$3,000. Once we caught the root cause, fixed the join, rebuilt the Gold table, and retrained the model, the predictions came back down to earth and the implied average ticket size — revenue divided by order count — started making sense in the $20-$29 range. This sort of catch is still a human-driven value add. I also noticed Tips, which are only enabled on Online Orders, for reasons I don’t entirely understand, were flowing into Net Revenue. Big no-no.
We also discovered that Spark SQL doesn't support FIRST(col ORDER BY other_col) syntax like PostgreSQL does. And that sample_weight in Prophet's model.fit() isn't supported in the serverless-installed version. And that moving a notebook from Drafts to a shared workspace folder breaks the job task path references. Each of these is the kind of thing that costs a consulting engagement a day or two of billable debugging. With Claude, we caught and fixed them in seconds. These are examples of things that Claude figured out for me. And more often than not, solved for before I knew it was a problem. Candidly, I don’t think I knew this until the time of writing this blog together.
What This Means for Data Engineering Consulting
I say this with genuine affection for my colleagues in the data engineering world, because I have spent years selling their services: the ground is shifting under this business model.
The traditional engagement goes something like this: a client needs a data pipeline. They hire a firm. The firm scopes the work, assembles a team, runs a discovery phase, builds out the architecture, writes the code, documents it, hands it over, and charges somewhere between $150 and $400 an hour for all of the above. Two yeas ago, for a project like what I just described — Bronze/Silver/Gold medallion architecture, API ingestion, weather integration, ML forecasting with MLflow, nightly scheduling — you're probably looking at an 8-16 week engagement at a meaningful blended rate.
Folks: I built it in a weekend, often while playing games on my other monitor. With an AI. For the cost of a Claude Max subscription and some Databricks compute that I think is going to total around $50, give or take.
Now — and this is important — I want to be clear about what I had going for me. I have spent years at Databricks selling professional services. I understand the concepts, the lingo, even if I hadn't implemented them myself. I’ve done much the same work in other platforms, like Alteryx, that I was doing today. I knew enough to ask the right questions, push back when something felt architecturally wrong, and insist on doing things properly rather than patching symptoms. When Claude tried to fix a broken forecast by throwing code into a notebook rather than fixing the underlying join bug, I was the one who said "wait, let's step back and think about the root cause." That instinct matters enormously.
I'm not saying data engineering expertise is obsolete…
I'm saying the delivery model for this sort of expertise is changing in ways that should make everyone in this space think carefully.
What's changing rapidly is the ratio: The ratio of experienced human judgment to commodity implementation work is shifting dramatically in favor of judgment. The judgment — knowing what to build, why this architecture and not that one, when to be suspicious of a number, what the business actually needs from its data — that's worth as much as it ever was. Maybe more, because now the implementation can move so fast that bad architectural decisions compound just as quickly as good ones.
What's diminishing in value is the pure hours of writing boilerplate pipeline code, setting up MERGE statements, fixing timezone issues, debugging Spark SQL syntax errors. An AI assistant can do a lot of that work. Not all of it, not without supervision, and not without someone who knows enough to catch it when it's wrong. But enough of it that a 12-week engagement for a reasonably straightforward data pipeline feels increasingly hard to justify.
The Good News: What This Means for Small Businesses
Here's the thing that actually keeps me up at night, in a good way.
For the past decade or so, sophisticated data infrastructure has been the exclusive province of companies with budgets large enough to hire data teams or engage consulting firms. A retailer with three locations and $5M in revenue doesn't get a medallion lakehouse architecture with ML forecasting. They get a spreadsheet and maybe a Shopify analytics dashboard.
What I built at Three Sisters Provisions is — objectively — more sophisticated than what most mid-market retailers have. A nightly-retraining Prophet model with cross-validation, hyperparameter tuning, seasonal priors from comparable historical data, confidence intervals, and forecast accuracy tracking by horizon day. A validation layer that reconciles Gold against Silver on every run and fails loudly on data quality issues. Full Unity Catalog metadata with column-level comments. A reference table architecture so special events are maintained in one place and all downstream models pick them up automatically.
I'm a mom-and-pop grocery store. We sell sandwiches and wine and the best sourdough on the South Shore: Kneady Mama bread. And I have a more rigorous analytics stack than most companies ten times our size.
That gap — between what sophisticated businesses have and what small businesses have — is compressing fast. The question for small business owners isn't really "can I afford enterprise-grade analytics?" anymore. The question is "do I understand my own business well enough to direct an AI to build it for me?"
That second question is harder than it sounds. You need to know what questions you want to answer. You need to understand enough about your data to catch it when something looks wrong. You need to be willing to go slowly on architecture decisions even when the temptation is to just get something running. And you need the patience to iterate — because the first version of anything will have bugs, and finding them is part of the process.
But if you have those things? The tools are there.
What This Means for Businesses That Aren't Plugged In
This is the part I find most interesting from a macro perspective.
There's a class of business — probably the majority of businesses — that is going to wake up in three to five years and find that their competitors who embraced this shift have a genuinely unfair informational advantage. Not because they bought expensive software. Not because they hired an army of data scientists. But because they spent some time learning to work with AI tools rather than waiting for someone to hand them a finished product.
The gap between plugged-in and not-plugged-in isn't a technology gap. Databricks has a free tier. Claude has plans that cost less than a dinner out. The gap is a curiosity and willingness gap. The businesses that win in this new world are going to be the ones where the owner, or someone close to the owner, got curious about what was possible and started experimenting.
I'm not a data engineer. I'm a reformed Sales Ops Analyst and an unrepentant sales guy with a blog called questionable decision-making. And I built a production ML forecasting pipeline. In a weekend.
The tools are genuinely accessible now. The question is whether you're willing to pick them up.

Claude - if Claude were sent back in time to kill me.
What I haven't told you yet is what happened when I decided to stop dabbling and go all-in with my new bestie, Claude.
Over the past few days, I sat down with Claude — Anthropic's AI, which I've been using in a Claude Project specifically dedicated to this work — and we built something I genuinely didn't think was possible without a team of data engineers and several weeks of billable hours.
Let me tell you what we built. And then let me tell you why it matters way beyond my wife’s adorable little store.
The Stack
Here's what's running nightly at Three Sisters Provisions:
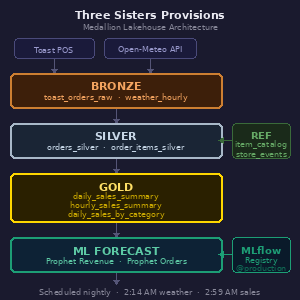
Quick Medallion Architecture Diagram
A Bronze layer pulls raw orders data from the Toast POS API and weather data from Open-Meteo's historical archive and forecast APIs.
Silver transforms and cleans that raw data — exploding order line items, fixing time zone issues (Toast stores timestamps in UTC, which caused some fun debugging), and building out a clean order and items table.
Gold aggregates everything into three production tables: a daily sales summary with weather, an hourly sales summary for the "how are we doing today" view, and a daily category breakdown showing revenue by product category.’

Illuminate the future, Saint Zuck
On top of that, we built a few Prophet-based machine learning forecast models — one for revenue, one for order count — both logged and versioned in MLflow, registered in the Databricks Model Registry with a @production alias, and running nightly to write 30 days of forward predictions into the same Gold table alongside the actuals.
The whole thing runs as scheduled Databricks jobs.
Weather ingests at 2:14 AM. Sales ingests and transforms and rolls up to Gold starting at 2:59 AM. Forecast generation runs after that. Every morning when I wake up, the data is current and the next 30 days of predictions are fresh.
I also built a reference table for special events — town strolls, catering days, future closures — with a little management notebook so my wife or or nephew can log a new event without touching a line of model code.
Oh, and there's a validation cell in the Gold notebook that actually asserts revenue matches Silver within 1% tolerance and will fail the job loudly if something's wrong. Because silent bad data is worse than no data.
The Mistakes Were Educational
I would be doing you, dear reader, a disservice if I made this sound entirely smooth. It was not entirely smooth.
We discovered about halfway through that a join between the orders table and the items table was multiplying revenue by the average number of items per order — roughly 4.3x inflation on every single number. The forecast model trained on those numbers for a while before we caught it. The result was a Friday revenue prediction of $7,646 when actual Friday revenue tends to be closer to $2,500-$3,000. Once we caught the root cause, fixed the join, rebuilt the Gold table, and retrained the model, the predictions came back down to earth and the implied average ticket size — revenue divided by order count — started making sense in the $20-$29 range. This sort of catch is still a human-driven value add. I also noticed Tips, which are only enabled on Online Orders, for reasons I don’t entirely understand, were flowing into Net Revenue. Big no-no, but so infrequent the sampling algo missed them.
In a different sense, Claude also discovered that Spark SQL doesn't support FIRST(col ORDER BY other_col) syntax like PostgreSQL does. And that sample_weight in Prophet's model.fit() isn't supported in the serverless-installed version. And that moving a notebook from Drafts to a shared workspace folder breaks the job task path references. Each of these is the kind of thing that costs a consulting engagement a day or two of billable debugging. With Claude, he* possibly she*, caught and fixed them in seconds. These are examples of things that Claude figured out for me. And more often than not, solved for before I knew it was a problem. Candidly, I don’t think I even knew this until the time of writing this blog together.
What This Means for Data Engineering Consulting
I say this with genuine affection for my colleagues in the data engineering world, because I have spent years selling their services: the ground is shifting under this business model.
The traditional engagement goes something like this: a client needs a data pipeline. They hire a firm. The firm scopes the work, assembles a team, runs a discovery phase, builds out the architecture, writes the code, documents it, hands it over, and charges somewhere between $150 and $400 an hour for all of the above. Two yeas ago, for a project like what I just described — Bronze/Silver/Gold medallion architecture, API ingestion, weather integration, ML forecasting with MLflow, nightly scheduling — you're probably looking at an 8-16 week engagement at a meaningful blended rate.
Folks: I built it in a weekend, often while playing games on my other monitor. For the cost of a Claude Max subscription and some Databricks compute that I think is going to total around $50, give or take.

Now — and this is important — I want to be clear about what I had going for me. I have spent years at Indicium AI and other firms selling professional services oriented around Databricks. I understand the platform, these concepts, the lingo, even if I hadn't implemented them myself. I’ve done much the same work in other platforms, like Alteryx, that I was doing in this project. And I know my wife’s business, because I helped build their tech stack, populate their item library, and so on. So, yeah, I knew enough to ask the right questions, push back when something felt architecturally wrong, and insist on doing things properly rather than patching symptoms. When Claude tried to fix a broken forecast by throwing code into a notebook rather than fixing the underlying join bug, I was the one who said "wait, let's step back and think about the root cause." That instinct matters enormously.
I'm not saying data engineering expertise is obsolete…
I'm saying the delivery model for this sort of expertise is changing in ways that should make everyone in this space think carefully.
What's changing rapidly is the ratio: The ratio of experienced human judgment to commodity implementation work is shifting dramatically in favor of judgment. The judgment — knowing what to build, why this architecture and not that one, when to be suspicious of a number, what the business actually needs from its data — that's worth as much as it ever was. Maybe more, because now the implementation can move so fast that bad architectural decisions compound just as quickly as good ones.
I’m proud to say that Indicium AI is leading the way. We’re an engineering-first organization and we aggressively measure, iterate, and ultimately improve upon our own value proposition.
What's diminishing in value is the pure hours of writing boilerplate pipeline code, setting up MERGE statements, fixing timezone issues, debugging Spark SQL syntax errors. An AI assistant can do a lot of that work. Not all of it, not without supervision, and not without someone who knows enough to catch it when it's wrong. But enough of it that a 12-week engagement for a reasonably straightforward data pipeline feels increasingly hard to justify.
The Good News: What This Means for Small Businesses
Here's the thing that actually keeps me up at night, in a good way.
For the past decade or so, sophisticated data infrastructure has been the exclusive province of companies with budgets large enough to hire data teams or engage consulting firms. A retailer with three locations and $5M in revenue doesn't get a medallion lakehouse architecture with ML forecasting. They get a spreadsheet and maybe a Shopify analytics dashboard.

What I built at Three Sisters Provisions is — objectively — more sophisticated than what most mid-market retailers have. A nightly-retraining Prophet model with cross-validation, hyperparameter tuning, seasonal priors from comparable historical data, confidence intervals, and forecast accuracy tracking by horizon day. A validation layer that reconciles Gold against Silver on every run and fails loudly on data quality issues. Full Unity Catalog metadata with column-level comments. A reference table architecture so special events are maintained in one place and all downstream models pick them up automatically.
I'm a mom-and-pop grocery store. We sell sandwiches and wine and the best sourdough on the South Shore: Kneady Mama bread. And I have a more rigorous analytics stack than most companies ten times our size.
That gap — between what sophisticated businesses have and what small businesses have — is compressing incredibly fast. The question for small business owners isn't really "can I afford enterprise-grade analytics?" anymore. The question is "do I understand my own business well enough to direct an AI to build it for me?"
That second question is harder than it sounds. You need to know what questions you want to answer. You need to understand enough about your data to catch it when something looks wrong. You need to be willing to go slowly on architecture decisions even when the temptation is to just get something running. And you need the patience to iterate — because the first version of anything will have bugs, and finding them is part of the process.
But if you have those things? The tools are there.
What This Means for Businesses That Aren't Plugged In
This is the part I find most interesting from a macro perspective.
There's a class of business — probably the majority of businesses — that is going to wake up in three to five years and find that their competitors who embraced this shift have a genuinely unfair informational advantage. Not because they bought expensive software. Not because they hired an army of data scientists. But because they spent some time learning to work with AI tools rather than waiting for someone to hand them a finished product.
The gap between plugged-in and not-plugged-in isn't a technology gap. Databricks has a free tier. Claude has plans that cost less than a dinner out. The gap is a curiosity and willingness gap. The businesses that win in this new world are going to be the ones where the owner, or someone close to the owner, got curious about what was possible and started experimenting.
I'm not a data engineer. I'm a reformed Sales Ops Analyst and an unrepentant sales guy with a blog called questionable decision-making. And I built a production ML forecasting pipeline. In a weekend.
The tools are genuinely accessible now. The question is whether you're willing to pick them up.
A Word to Anyone Who Thinks They Can Go It Alone
Here's something I need to say directly to a specific group of people, because I care about you: the lone coders, the self-taught data analysts, the "I'll just Google it" crowd, the folks who have built their professional identity around being the person who figures things out without help and hasn’t already embraced AI tools: That identity, held too tightly, is going to become a liability.
The pace of change in this space right now is unlike anything I've witnessed in my career, and I watched Tableau eat the Cognos world, Alteryx ruin the hand-crafted Excel pivot table market, and Databricks eat pretty much everything else since then. Each of those transitions took years, and in some ways are still happening, and that time has given people the space they need to learn, grow, and adapt.
This one is different. AI tools are not just getting better — they are getting better faster than any individual can keep up with by working alone. They are probably better than you, technically, at anything you think you’re an expert at.*
I caught more bugs, made better architectural decisions, and built more robust code in this project by treating Claude as a genuine collaborator than I ever would have grinding through it solo. Not because the AI is smarter than me — it isn't, and I had to correct it more than once on things where I knew better. But because two perspectives on a problem catch things one perspective misses, and because the AI has read more documentation, seen more Spark SQL edge cases, and encountered more MLflow gotchas than I ever will on my own.
The developers and analysts I worry about are the ones who see AI assistance as a crutch, or worse, as a threat to their credibility. "Real engineers write their own code." "If I use AI to help me, is it really my work?" I understand those feelings. I have had them myself. They are the wrong framework entirely.
The right framework is this: a plumber who refuses to use power tools because "real plumbers use hand tools" is not more skilled than a plumber who uses both. They are slower, more expensive, and more error-prone. The skill is in knowing what to build and why, not in the manual labor of building it.
“A surgeon who refuses to use modern imaging equipment because their predecessors operated by feel alone is not more admirable. They are just more dangerous.”
The professionals who will thrive in tomorrow's landscape are not the ones who can write the most code. They are the ones who can direct, verify, architect, question, and judge the output of systems that write code. The ones who know enough to catch it when the AI confidently produces a join that inflates revenue by 4.3x and nobody notices for two weeks. The ones who push back when a quick patch is offered instead of a root cause fix.
If you are a coder or an analyst who has not yet seriously invested in learning to work with these tools, not against them and not in ignorant bliss of them — I'm not judging you. I'm urging you. The window to adapt on your own terms, at your own pace, is open right now. It will not stay open indefinitely. The colleagues who are already moving will not wait for the rest of the field to catch up.
Go build something. Break it. Fix it. Ask for help. That last part used to mean asking a colleague or posting on Stack Overflow. It still means those things. It also means something new now, and the sooner you make peace with that, the better off you'll be.
Three Sisters Provisions is a grocery, café, and wine shop in Cohasset, MA. If you're on the South Shore and you haven't stopped in, please remedy that. We have excellent sandwiches, a thoughtful wine selection, and yes, we now have nightly ML forecast models running on our sales data. You can reach Joe at the contact form above, or find him in the store most mornings, probably arguing with a Databricks notebook.